日前,理想汽車發(fā)布下一代自動(dòng)駕駛架構(gòu)MindVLA。MindVLA是一個(gè)能與用戶溝通、理解用戶意圖的智能體,可以理解為是一名能聽懂用戶說話的專職機(jī)器人司機(jī)。MindVLA是一種視覺-語言-行為大模型,是機(jī)器人大模型的新范式,它將空間智能、語言智能和行為智能統(tǒng)一在一個(gè)模型里。據(jù)悉,MindVLA將在7月份與理想i8同步推出,現(xiàn)款搭載英偉達(dá)雙Orin X芯片的車型也同樣能支持MindVLA。

MindVLA將為用戶帶來全新的產(chǎn)品形態(tài)和產(chǎn)品體驗(yàn),有MindVLA賦能的汽車是聽得懂、看得見、找得到的專職司機(jī)。“聽得懂”是用戶可以通過語音指令改變車輛的路線和行為,例如用戶在陌生園區(qū)尋找超市,只需要通過理想同學(xué)對(duì)車輛說:“帶我去找超市”,車輛將在沒有導(dǎo)航信息的情況下,自主漫游找到目的地;車輛行駛過程中,用戶還可以跟理想同學(xué)說:“開太快了”“應(yīng)該走左邊這條路”等,MindVLA能夠理解并執(zhí)行這些指令。

“看得見”是指MindVLA具備強(qiáng)大的通識(shí)能力,不僅能夠認(rèn)識(shí)星巴克、肯德基等不同的商店招牌,當(dāng)用戶在陌生地點(diǎn)找不到車輛時(shí),可以拍一張附近環(huán)境的照片發(fā)送給車輛,擁有MindVLA賦能的車輛能夠搜尋照片中的位置,并自動(dòng)找到用戶。

“找得到”意味著車輛可以自主地在地庫、園區(qū)和公共道路上漫游,其中典型應(yīng)用場景是用戶在商場地庫找不到車位時(shí),可以跟車輛說:“去找個(gè)車位停好”,車輛就會(huì)自主尋找車位,即便遇到死胡同,車輛也會(huì)自如地倒車,重新尋找合適的車位停下,整個(gè)過程不依賴地圖或?qū)Ш叫畔?,完全依賴MindVLA的空間理解和邏輯推理能力。
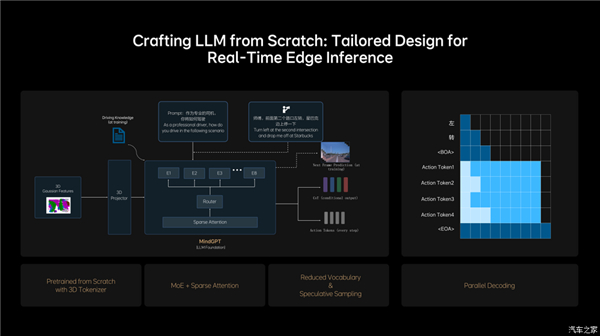
MindVLA利用Diffusion將Action Token解碼成優(yōu)化的軌跡,并通過自車行為生成和他車軌跡預(yù)測的聯(lián)合建模,提升了在復(fù)雜交通環(huán)境中的通行能力。面對(duì)部分長尾場景,理想建立起人類偏好數(shù)據(jù)集,并且創(chuàng)新性地應(yīng)用RLHF(基于人類反饋的強(qiáng)化學(xué)習(xí))微調(diào)模型的采樣過程,最終使MindVLA能夠?qū)W習(xí)和對(duì)齊人類駕駛行為,顯著提升自動(dòng)駕駛系統(tǒng)的安全下限。